
Comprendre l’IA : pourquoi expliquer ses décisions est un défi ?

- L’opacité des systèmes d’IA limite la compréhension de leurs décisions, ce qui complique la détection des erreurs, l’identification des biais et l’attribution des responsabilités.
- Les modèles les plus performants sont souvent les plus complexes, rendant difficile leur interprétation et posant un dilemme entre efficacité et transparence.
- L’explicabilité constitue une piste pour faire face à l’opacité des modèles d’IA, à travers des techniques d’analyse a posteriori ou la conception de modèles intrinsèquement plus lisibles.
L’Intelligence Artificielle est aujourd’hui partout et influence de plus en plus notre quotidien : elle recommande des films, assiste les médecins et oriente même certaines décisions juridiques. Le plus souvent, ses décisions sont pertinentes, efficaces, et semblent répondre à nos attentes. Une plateforme de streaming peut suggérer un film adapté à nos goûts, et un algorithme médical peut détecter une anomalie sur une radiographie. Pourtant, les mécanismes qui sous-tendent ces choix restent souvent opaques. En effet, les algorithmes traitent d’énormes volumes de données et établissent des corrélations que même leurs concepteurs ne peuvent pas toujours expliquer. Cette opacité soulève des enjeux majeurs, notamment en matière de confiance, de responsabilité et de prise de décision partagée entre humains et machines.
C’est dans cette perspective que s’est développé le domaine de l’explicabilité de l’IA, ou eXplainable AI (XAI), qui étudie comment les systèmes d’intelligence artificielle peuvent rendre leurs décisions compréhensibles pour les utilisateurs (Gunning et al., 2019). L’objectif est de rendre ces décisions compréhensibles et interprétables, afin de favoriser la confiance, améliorer la collaboration entre humains et machines, et permettre aux utilisateurs de rester impliqués dans le processus décisionnel plutôt que d’en être exclus. Ces enjeux ont conduit à un intérêt croissant pour la XAI dans la littérature scientifique.
De nombreux travaux explorent différentes approches pour améliorer la transparence des algorithmes, qu’il s’agisse de développer des modèles intrinsèquement interprétables ou de proposer des méthodes d’explication a posteriori pour rendre les systèmes existants plus lisibles. Cette recherche s’inscrit dans un contexte où la compréhension des mécanismes de l’IA devient essentielle, tant pour son acceptation par le grand public que pour son encadrement par des réglementations.
Au-delà des contraintes légales, les pouvoirs publics, les entreprises et les chercheurs s’interrogent sur la manière d’intégrer ces principes d’explicabilité sans compromettre la performance des modèles. Loin d’être un simple défi technique, cette question touche à des enjeux sociétaux fondamentaux : comment garantir que l’IA reste un outil au service des citoyens et non une entité opaque qui peut échapper au contrôle des opérateurs humains ?
Pour mieux saisir cette question, nous verrons d’abord pourquoi il est difficile d’expliquer les décisions d’une IA, en explorant la complexité des modèles actuels. Nous aborderons ensuite les enjeux de cette opacité, qu’ils concernent la confiance, la responsabilité ou la réglementation. Enfin, nous examinerons les solutions proposées pour rendre l’IA plus transparente et les limites qu’elles rencontrent.
La complexité des modèles d’IA
Un enjeu sociétal
Les systèmes d’IA les plus performants reposent sur des architectures de plus en plus sophistiquées, en particulier l’apprentissage profond (deep learning). Ces modèles, composés de réseaux de neurones artificiels contenant parfois des milliards de paramètres, traitent l’information de manière non linéaire et multidimensionnelle. Contrairement aux modèles plus simples, comme les arbres de décision ou les régressions linéaires, ils ne permettent pas d’expliquer directement comment une prédiction a été obtenue. On parle alors de « boîte noire » : l’IA donne un résultat, mais sans que l’on puisse toujours retracer précisément son raisonnement. Cette opacité soulève une tension entre performance et transparence, connue sous le nom de performance-transparency trade-off (Gunning & Aha, 2019). En règle générale, plus un modèle est performant, plus il est complexe et difficile à interpréter.
L’explicabilité, l’interprétabilité et la transparence sont trois notions étroitement liées mais distinctes lorsqu’il s’agit de comprendre le fonctionnement de l’IA :
- L’explicabilité désigne la capacité à fournir une justification compréhensible des décisions prises par un modèle, qu’elle soit destinée à un expert technique ou à un utilisateur non spécialisé. –
- L’interprétabilité se réfère à la facilité avec laquelle un humain peut analyser et anticiper le comportement d’un modèle sans nécessiter d’explication externe. Un modèle interprétable est donc intrinsèquement compréhensible, tandis qu’un modèle opaque peut nécessiter des méthodes spécifiques pour en expliquer les décisions.
- La transparence implique l’accessibilité des informations sur la structure et le fonctionnement interne d’un système d’IA, y compris ses données d’entraînement, ses paramètres et ses critères de décision. Ces concepts sont au cœur de la recherche en eXplainable AI (XAI), qui vise à concevoir des modèles plus compréhensibles et mieux adaptés à une utilisation responsable.
Les approches les plus avancées, comme les grands modèles de langage ou les réseaux convolutifs en vision par ordinateur, surpassent largement les méthodes classiques en termes de précision, mais au prix d’une perte de lisibilité. Cette situation complique non seulement la compréhension des décisions prises, mais aussi la correction d’éventuelles erreurs, ce qui souligne l’importance de développer des approches visant à améliorer l’explicabilité de ces modèles.
L’explicabilité ne se limite pas à comprendre les choix d’un modèle, elle permet aussi de détecter les éventuels biais qu’il pourrait contenir. Une IA apprend à partir de données existantes, qui peuvent refléter des inégalités ou des tendances discriminatoires présentes dans la société, ou dans les données utilisées à entrainer le modèle. Par exemple, un algorithme de recrutement entraîné sur des données historiques pourrait montrer une préférence pour les profils ayant déjà été sélectionnés par le passé. Si ces choix reflètent un biais humain, il existe un risque que l’algorithme le reproduise, voire même le renforce. Même lorsque l’IA semble donner des résultats pertinents, elle peut en réalité s’appuyer sur des critères discutables, comme des corrélations trompeuses plutôt que de véritables relations de cause à effet. Sans mécanismes d’explication, ces biais restent invisibles et risquent d’entraîner des décisions injustes.
L’opacité de l’IA devient particulièrement problématique lorsqu’elle est utilisée dans des domaines à fort impact social. En santé, des algorithmes sont utilisés pour analyser des images médicales et détecter d’éventuelles pathologies, mais si leur fonctionnement reste incompréhensible pour les médecins, il devient difficile d’évaluer la fiabilité des diagnostics. De même, dans le domaine judiciaire, certains outils d’évaluation des risques de récidive influencent les décisions de justice, mais leur fonctionnement interne est rarement accessible aux magistrats. Au-delà du manque de transparence dans la prise de décision, cette opacité soulève une autre difficulté majeure : comment corriger un algorithme ou le faire évoluer si l’on ne peut pas comprendre son raisonnement ? Lorsqu’une erreur est détectée, il est souvent impossible d’identifier précisément les facteurs qui y ont conduit, rendant la correction complexe. Sans explicabilité, il devient donc non seulement difficile de faire confiance à ces systèmes, mais aussi de les améliorer de manière ciblée. Une IA opaque peut ainsi produire des erreurs qui passent inaperçues, entraînant des décisions injustes ou discriminatoires, sans qu’il soit possible de les détecter, ni d’en corriger la cause efficacement. Il est à noter que corriger ces erreurs suppose non seulement d’expliquer les décisions d’un modèle, mais aussi de comprendre son fonctionnement global. Sans une connaissance minimale des principes qui sous-tendent l’IA, les explications fournies risquent d’être mal interprétées ou insuffisantes pour ajuster efficacement le système.
De plus, la mise en place de l’explicabilité de l’IA ne relève pas uniquement d’un défi technique : elle conditionne la manière dont ces systèmes sont perçus et acceptés par la société. Une IA dont les décisions sont compréhensibles inspire davantage confiance, facilite la prise de responsabilité en cas d’erreur et permet de respecter les exigences légales en matière de transparence.
Pour qu’une technologie soit adoptée à grande échelle, elle doit être perçue comme fiable (Miller, 2019). Si le manque de compréhension du fonctionnement d’une IA peut freiner son adoption dans certains contextes, notamment en médecine ou en finance où la transparence est essentielle, il n’est pas toujours un obstacle. L’exemple de ChatGPT montre qu’une technologie peut être largement utilisée, même si ses mécanismes internes restent obscurs pour la plupart des utilisateurs. Son accessibilité et son efficacité perçue semblent suffire à encourager son adoption, malgré l’absence d’une compréhension détaillée de son fonctionnement.
L’absence d’explicabilité pose également un problème de responsabilité. Si une IA prend une mauvaise décision, qui en assume les conséquences ? Un diagnostic erroné, une discrimination dans un recrutement ou une erreur dans l’attribution d’un crédit bancaire peuvent avoir des impacts lourds sur des individus. Sans une compréhension claire du fonctionnement du modèle, il est complexe de savoir dans quelle mesure la responsabilité incombe aux concepteurs ou aux utilisateurs.
Les exigences règlementaires
Face aux défis posés par l’opacité des systèmes d’intelligence artificielle, les pouvoirs publics imposent progressivement des exigences accrues en matière d’explicabilité. La transparence des algorithmes devient un enjeu central du débat public et de la régulation. Ces dernières années, plusieurs cadres législatifs ont émergé pour garantir une meilleure compréhension des décisions automatisées et renforcer la confiance des utilisateurs.
En Europe, le Règlement Général sur la Protection des Données (RGPD), entré en vigueur en 2018, introduit un « droit à l’explication » pour les décisions prises par des algorithmes lorsqu’elles ont un impact significatif sur les individus. Cette réglementation impose aux organisations d’expliquer, dans des termes compréhensibles, le fonctionnement des systèmes d’IA utilisés dans des processus décisionnels automatisés affectant les droits des citoyens.
Plus récemment, en 2024, l’Union européenne a adopté l’AI Act, actuellement en cours de mise en œuvre. Cette réglementation vise à encadrer le développement et l’utilisation des IA en classant les systèmes selon leur niveau de risque. Les modèles jugés à « haut risque », notamment ceux utilisés dans des domaines sensibles comme la santé, la finance ou la justice, devront respecter des exigences strictes en matière de transparence, de traçabilité et d’explicabilité. L’AI Act impose également aux entreprises de prouver que leurs systèmes sont non seulement compréhensibles par les utilisateurs finaux, mais aussi auditable par des régulateurs indépendants (Article 50 de l’AI Act).
Ces réglementations posent un défi technique majeur : comment concilier transparence et performance dans des modèles d’IA toujours plus complexes ? Les méthodes actuelles d’explication restent imparfaites et peuvent, dans certains cas, simplifier à l’excès des décisions en réalité bien plus nuancées. Trouver le bon équilibre entre interprétabilité et efficacité est ainsi devenu l’un des enjeux centraux du développement de l’intelligence artificielle.
Quelles solutions existent pour rendre l’IA explicable ?
Face aux défis posés par l’opacité des modèles d’intelligence artificielle, plusieurs approches ont été développées pour améliorer leur explicabilité (Speith, 2022). Ces solutions passent par des techniques d’analyse post-hoc ou l’utilisation de modèles plus transparents dès leur conception.
Une première approche consiste à expliquer le fonctionnement d’un modèle après son entraînement, sans modifier son architecture. Par exemple, certaines méthodes permettent de visualiser les zones d’une image qui ont influencé la décision d’un réseau de neurones. Des techniques comme Grad-CAM génèrent des cartes de chaleur qui mettent en évidence les régions les plus déterminantes dans une classification d’image (Fig. 1).

Pour les algorithmes de prédiction et de classification, des outils comme LIME (Local Interpretable Model-agnostic Explanations) et SHAP permettent d’identifier les facteurs qui ont influencé une décision donnée. LIME construit des approximations locales du modèle pour comprendre son comportement sur un cas précis, tandis que SHAP applique des principes issus de la théorie des jeux pour attribuer un poids à chaque variable d’entrée (Fig. 2).
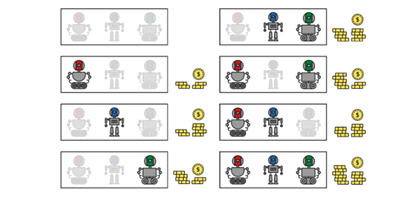
Ces méthodes ne permettent toutefois qu’une compréhension partielle et peuvent parfois donner des explications simplifiées ou biaisées par rapport au fonctionnement réel du modèle.
Une autre approche repose sur l’utilisation de modèles intrinsèquement explicables, c’est-à-dire conçus dès le départ pour être compréhensibles (Rudin, 2019). Contrairement aux réseaux de neurones profonds, les arbres de décision ou les régressions linéaires permettent d’identifier clairement les critères qui ont conduit à une décision, car leurs mécanismes reposent sur des règles explicites et lisibles. Des efforts sont également faits pour améliorer la transparence des réseaux de neurones eux-mêmes. Certains modèles intègrent des mécanismes d’attention qui permettent de mieux comprendre quels éléments ont influencé une prédiction. Dans le traitement du langage naturel, ces systèmes mettent en évidence les mots ou phrases ayant eu le plus de poids dans la décision finale, rendant l’interprétation plus accessible.
Cependant, aucune solution ne permet encore de concilier pleinement performance et transparence. Les modèles interprétables sont plus faciles à comprendre, mais leur simplicité peut limiter leur efficacité. À l’inverse, les modèles plus complexes, bien que performants, restent difficiles à expliquer de manière fiable. Cette difficulté montre l’importance de poursuivre la recherche sur l’explicabilité afin de rendre l’IA plus compréhensible et mieux encadrée dans ses usages.
CONCLUSION
À mesure que l’IA prend une place croissante dans nos sociétés, la question de la compréhension de ses mécanismes de décision se pose. L’opacité de ces systèmes peut limiter leur acceptation par les utilisateurs rendant leur intégration plus complexe et soulevant des questions sur leur contrôle et leur régulation. L’explicabilité apparait ainsi comme un élément essentiel pour renforcer la confiance, garantir une utilisation éthique et répondre aux exigences réglementaires. Pourtant, rendre une IA compréhensible reste une tâche complexe. Les modèles les plus avancés sont souvent aussi les plus difficiles à interpréter, et les méthodes actuelles, bien qu’apportant des éléments de compréhension, ne permettent pas toujours d’éclairer pleinement les décisions de ces systèmes. Trouver un équilibre entre transparence et efficacité représente donc un défi majeur dans le développement de ces technologies.
Mais une question demeure : suppose-t-on trop rapidement que l’explicabilité favorise nécessairement l’acceptation et l’usage des IA ? L’idée selon laquelle une meilleure transparence entraînerait automatiquement une plus grande confiance et adoption est rarement remise en question. Pourtant, les effets réels de l’explicabilité ne sont pas toujours démontrés. Une explication détaillée d’un algorithme garantit-elle vraiment une meilleure compréhension par l’utilisateur ? Et si tel est le cas, cela signifie-t-il qu’il prendra des décisions plus éclairées ? De plus, il faut s’interroger sur la pertinence de toujours chercher à expliquer : doit-on tout rendre compréhensible, même lorsque cela ne change pas réellement la manière dont un système est utilisé ?
Au-delà des solutions techniques pour rendre l’IA plus explicable, l’utilisation de ces systèmes passe aussi par une meilleure formation des utilisateurs. Les décideurs politiques, industriels et professionnels des secteurs concernés doivent être formés non seulement aux limites et aux risques de l’IA, mais aussi à son fonctionnement. En effet, pour véritablement saisir les enjeux de l’explicabilité, il est essentiel de comprendre comment ces systèmes prennent leurs décisions. Le développement de contenus pédagogiques et d’initiatives de formation permettrait de mieux armer les décideurs, ainsi que les citoyens, face aux décisions automatisées qui influencent de plus en plus leur quotidien.
L’avenir de l’intelligence artificielle ne se joue donc pas uniquement sur le plan technique, mais aussi dans la manière dont nous choisissons de l’intégrer à nos sociétés. Comment parvenir à une IA à la fois performante et compréhensible, qui inspire confiance sans sacrifier son efficacité ? Ce défi reste ouvert aux chercheurs, ingénieurs et décideurs, qui devront concilier innovation et transparence pour construire les systèmes intelligents de demain.
RÉFÉRENCES
Devoteam. (2020). Algorithme N°7 – LIME ou SHAP pour comprendre et interpréter vos modèles de machine learning ? Devoteam France. Retrieved February 12, 2025, from https://france.devoteam.com/paroles-dexperts/algorithme-n7-lime-ou-shap/
Gunning, D., & Aha, D. (2019). DARPA’s Explainable Artificial Intelligence (XAI) Program. AI Magazine, 40(2), 44-58. https://doi.org/10.1609/aimag.v40i2.2850
Gunning, D., Stefik, M., Choi, J., Miller, T., Stumpf, S., & Yang, G.-Z. (2019). XAI—Explainable artificial intelligence. Science Robotics, 4(37), eaay7120. https://doi.org/10.1126/scirobotics.aay7120
Kassel, R. (2021, July 9). Qu’est-ce que la méthode Grad-CAM ? Formation Data Science | DataScientest.com. https://datascientest.com/grad-cam
Miller, T. (2019). Explanation in artificial intelligence: Insights from the social sciences. Artificial Intelligence, 267, 1–38. https://doi.org/10.1016/j.artint.2018.07.007
Parlement Européen. (2024). Chapter IV: Transparency Obligations for Providers and Deployers of Certain AI Systems | EU Artificial Intelligence Act. https://artificialintelligenceact.eu/chapter/4/
Rudin, C. (2019). Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nature machine intelligence, 1(5), 206-215.
Speith, T. (2022). A Review of Taxonomies of Explainable Artificial Intelligence (XAI) Methods. 2022 ACM Conference on Fairness, Accountability, and Transparency, 2239–2250. https://doi.org/10.1145/3531146.3534639
Articles similaires

Nous proposons une analyse critique de l’écoconception des services numériques en la replaçant dans la structure globale de l’empreinte environnementale du secteur.

L’IA s’invite au cœur des rédactions historiques : automatisation, hiérarchisation algorithmique, personnalisation… mais à quel prix pour la singularité éditoriale et la confiance du public ?

Ce rapport propose une lecture analytique des tendances en cours et des leviers permettant aux banques de se préparer aux paiements démonétisés.