
Ceci n’est pas un (énième) article sur le prompt engineering…

- Le succès des outils d’IA ne dépend pas seulement de la qualité des prompts, mais de leur capacité à s’inscrire dans des pratiques collectives et des logiques organisationnelles existantes.
- Les techniques récentes d’autoprompting et d’inverse prompting déplacent le rôle humain, de la formulation des commandes vers la supervision, l’évaluation et l’orientation des systèmes.
- À mesure que les modèles gagnent en autonomie, la question centrale devient celle de l’alignement entre les productions de l’IA et les valeurs, objectifs et standards propres aux organisations.
- Le context engineering propose de dépasser une approche purement technique pour intégrer le contexte réel, la culture et les attentes implicites dans le fonctionnement des outils d’IA.
- Sans ce travail sur le contexte et le sens, les organisations courent le risque de laisser les systèmes d’IA façonner, par défaut, leurs manières de faire et leur identité.

Le prompt est associé à une description plus ou moins courte de la tâche souhaitée que l’on donne à l’outil d’IA dans nos usages quotidiens. Enracinée dans une logique selon laquelle la qualité de l’output dépend de celle de l’input, la qualité de l’instruction (le bon prompt) est identifiée comme la condition pour obtenir des résultats satisfaisants dans les demandes faites à un agent IA. Le prompt détermine la fidélité du contenu généré par rapport à l’intention de l’utilisateur, ce qui requiert une compétence en ingénierie fine afin d’obtenir les résultats au plus proche de la demande. Ainsi depuis deux ans on observe non sans une certaine méfiance, un tumulte de propositions de prompts à absolument maîtriser ou des formations autour du prompt engineering…
Certes, il faut savoir demander pour obtenir le résultat désiré. Ce faisant, l’utilisateur donne autant d’informations que possible sur la tâche, en espérant que l’outil lui fournira le résultat souhaité. Mais passé le cap des tâches individuelles quotidiennes, et replacé dans un environnement organisationnel, comment intégrer les outils dans une démarche collective ? Que se passe-t-il concernant la manière de voir et surtout de faire les choses au sein de l’organisation, autrement dit ses processus collectifs et son ton ?
Le prompt engineering en dit long sur les instructions menant à une tâche, mais ne nous dit pas grande chose sur la manière dont les choses sont faites au sein de l’organisation. La question est d’autant plus pressante que des développements récents ciblent des techniques d’autoprompting. La question est désormais non pas celle concernant le bon prompt, mais plutôt comment s’assurer que ces outils s’intègrent de manière autonome dans les processus de l’organisation, tout en gardant les standards et la manière de faire habituelle, celle qui est propre à l’organisation. Si en effet cette compétence devenait simplement une fonctionnalité de plus des agents conversationnels, comment aligner la vision de l’organisation avec l’autonomie des systèmes d’IA ?
Le context engineering apparaît comme une approche qui ajoute une couche plus profonde de réflexion, en travaillant davantage sur l’alignement entre les outils d’IA et l’organisation, ainsi que sur la traduction des caractéristiques propres à l’environnement dans la performance des outils. Le problème ? On a besoin d’un peu (beaucoup) d’intelligence humaine pour y parvenir.
D’abord, l’autoprompting…
Plusieurs études en cours explorent différentes techniques d’autoprompting, à la fois comme levier pour améliorer les commandes passées et donc les résultats obtenus, mais aussi pour dépasser l’effet black-box et partir des sorties textuelles pour reconstruire le prompt permettant d’obtenir le résultat indiqué.
Le reverse prompt engineering a été testé dans un cadre sans entraînement. A partir d’un résultat (les sorties textuelles d’un LLM), le modèle produit des candidats prompts de manière itérative et sélectionne le plus proche, qui permettrait d’obtenir le résultat indiqué. L’objectif de cette approche n’est pas de taper une commande à l’outil pour obtenir un résultat (ce qu’on fait quand on introduit des prompts), mais de présenter un résultat de qualité pour obtenir la commande qui pourrait permettre d’aboutir à ce résultat. Une étude de cas révèle l’intérêt de cette approche pour générer automatiquement du texte de qualité comparable à l’original. Cette technique peut représenter des avancées importantes en termes de prompt engineering, mais peut également poser des risques en termes de propriété intellectuelle, confidentialité ou sécurité des systèmes.
L’inverse prompting a démontré des résultats satisfaisants dans le sens d’une amélioration inhérente au système et permettant à l’outil de se prompter lui-même. Dans une étude récente des chercheurs ont notamment testé une méthode d’inverse prompting pour générer une planification de tâches (Lee et al., preprint). Cette méthode de raisonnement en plusieurs étapes génère d’abord l’action inverse du plan d’action produit, examine sa faisabilité et la compare avec le résultat de l’action inverse, générant du feedback. Le modèle fournit des justifications explicites au niveau du feedback, permettant au prompt de s’améliorer. Les chercheurs ont obtenu des résultats qui surpassent ceux des modèles LLM classiques en termes d’achèvement de tâches et d’autocorrection.
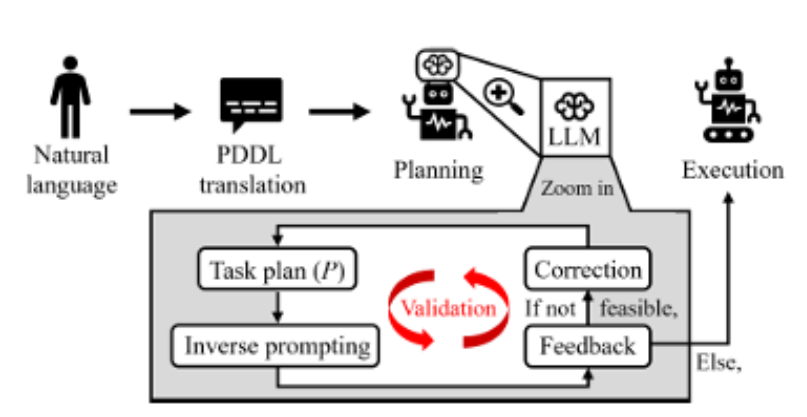
Enfin à titre d’exemple, des chercheurs explorent l’inverse prompting pour la détection des productions d’IA, en demandant au système d’imaginer quel aurait pu être le prompt permettant de produire un résultat déterminé (Chen et al., preprint).
Les utilisations de ces techniques sont nombreuses, par exemple pour industrialiser la production d’un contenu récurrent dont on est satisfait (des fiches produit, des évaluations, des offres d’emploi…). Cependant, il faut noter que malgré ces avancées techniques, plusieurs limites demeurent. Le prompt automatisé reste relativement exploratoire, il dépend de plusieurs variables comme notamment les données disponibles, peut représenter des risques importants en termes de confidentialité ou protection de la propriété intellectuelle et, en fin des comptes il ne dépasse pas systématiquement les performances du prompting manuel dans un nombre significatif de tâches.
Malgré cela, les résultats de ces recherches exploratoires ouvrent la voie à une réflexion plus large sur l’input humain dans les requêtes. Avec l’émergence d’outils automatisés capables d’inférer ou d’optimiser des prompts, le prompt engineering se redéfinit, et le rôle de l’humain avec. Alors qu’il s’agissait d’un rôle créatif basé souvent sur l’intuition, la connaissance du modèle et l’expérimentation, et visant à identifier les bonnes commandes pour obtenir le résultat désiré, le prompt engineering pourrait évoluer vers un rôle de supervision des prompts générés automatiquement. Cela exigerait potentiellement d’autres compétences d’ordre critique et analytique, afin de sélectionner, valider ou affiner des prompts formulés automatiquement. De la sorte, les relations humain-machine pourraient évoluer d’une relation basée sur la performance et l’efficacité vers un terrain de pertinence éthique et d’intentionnalité.
Ensuite, le context engineering
Au-delà des techniques d’inverse prompting, les avancées en IA font que les modèles les plus récents sont en mesure de déterminer la demande souhaitée sans recevoir des instructions trop complexes. Cela rend la plupart des conseils et astuces promues en ligne peu pertinentes pour la plupart des requêtes quotidiennes.
Par conséquent, l’ingénierie derrière les recherches ne concerne plus les instructions qui mènent à la réalisation d’une tâche. La question est comment donner à l’outil des données et des informations suffisantes pour prendre des bonnes décisions dans un cadre organisationnel donné, autrement dit dans un contexte spécifique ? C’est là qu’on parle de context engineering.
Contrairement à des instructions visant à préciser comment obtenir un résultat, le context engineering n’est pas une question de maîtrise technique (quels mécanismes mènent à quels résultats ?) mais plutôt une connaissance fine du contexte réel (l’environnement de la demande – comme une organisation, un groupe organisationnel, une direction, un objectif précis…). Ce qui est intéressant dans cette approche est que le résultat de l’instruction ne dépend pas d’une solution unique (one fits all ou LE prompt à maîtriser absolument) mais de la connaissance de comment fonctionne l’organisation, ses aspirations et ses valeurs. Quelle est la version idéale d’un compte-rendu, d’un rapport, d’un document ? Qu’est-ce qu’on attend au niveau organisationnel de tel processus ou de tel autre ? Il s’agit non seulement d’une version opérationnelle idéale pour le contexte organisationnel, mais aussi celle qui corresponde à la vision et au ton de l’organisation, autrement dit, à sa culture. Il est donc moins question d’un problème technique que d’un problème de fond qui concerne toutes les fonctions et les opérations de l’organisation.
C’est comme pour les humains. Avez-vous déjà essayé de demander à une personne fraîchement arrivée de produire un compte-rendu de réunion sans en connaître les tenants et les aboutissants ? Sans plus de brief en amont, le résultat est au mieux purement descriptif et largement perfectible. Pour l’IA c’est pareil : le résultat sera moins intéressant et désirable que si l’on donne un peu de contexte sur la teneur de la tâche, les objectifs et les résultats désirés.
En effet, le contexte est souvent négligé. Les implémentations actuelles d’IA dans les organisations se basent sur des fameux « use cases » dans une approche qu’on pourrait qualifier de naïve, où l’on met tout ce qu’on peut dans le chat en espérant obtenir les meilleurs résultats. Et fournir trop d’informations, ou des informations non pertinentes, peut facilement submerger un LLM et conduire à des réponses génériques et inutiles. L’ingénierie du contexte est trop souvent effacée.
Une simple question peut s’avérer utile : « Si je devais effectuer la tâche, quelles informations m’aideraient pour être plus proche de ma trajectoire ? ».
Les implications organisationnelles soulevés par cette réflexion sont considérables. Il ne s’agit pas simplement de nourrir l’IA avec des contenus existantes pour en reproduire des résultats similaires ; ni de développer des systèmes propres qui façonneraient la nouvelle manière de faire les choses. L’objectif est d’élargir les perspectives en IA et d’aller au-delà de la « simple » réalisation des tâches.
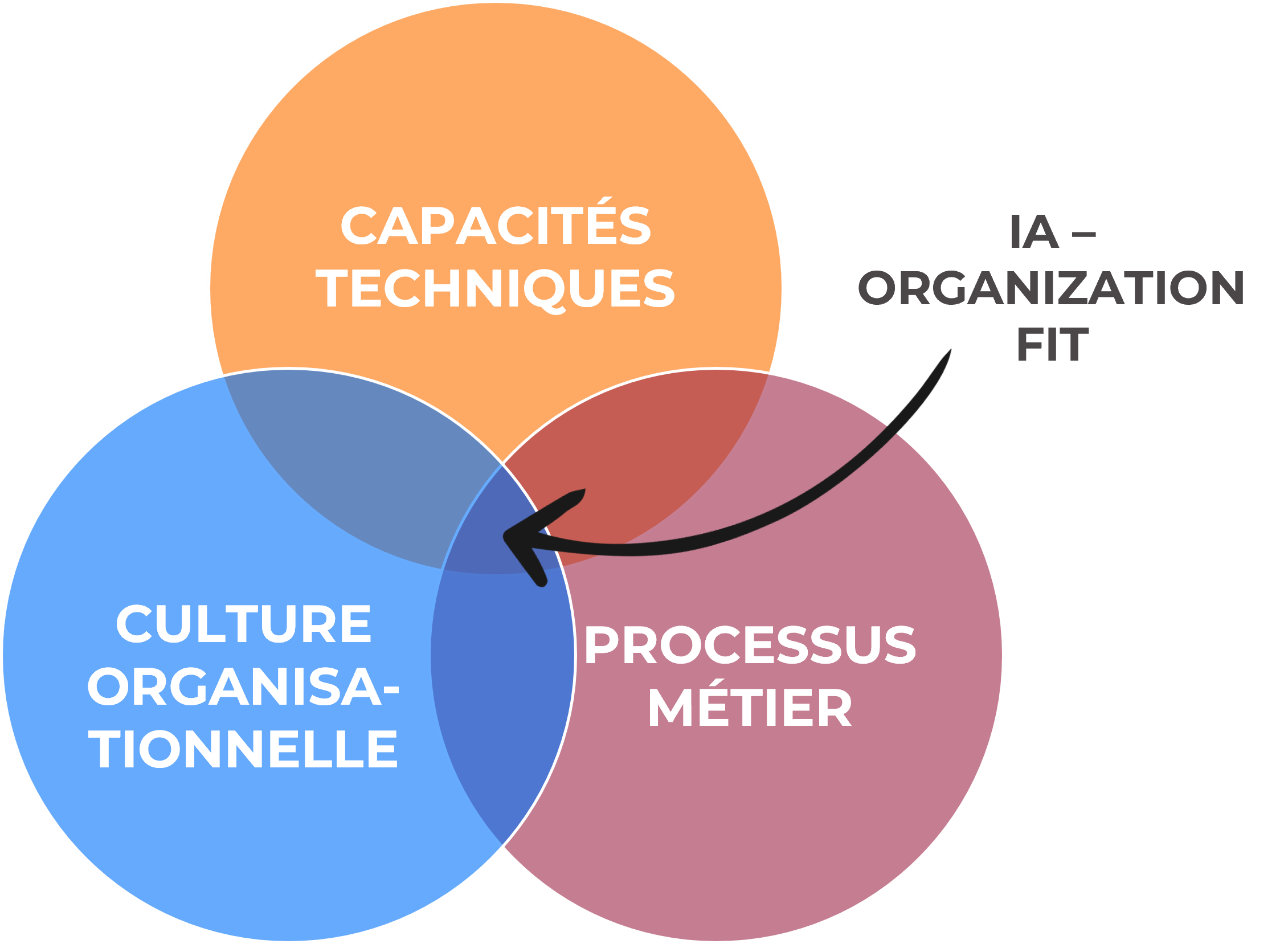
Dépassant les développements techniques, cette démarche engage une réflexion sur les ambitions, les aspirations, le ton et la voix de l’organisation. Une fois le contexte pris au sérieux, le véritable défi réside dans les choix à réaliser : quelles sont les aspirations que l’on souhaite refléter ? Comment s’assurer que les productions générées par l’IA incarnent ces objectifs de manière fidèle et cohérente ? À défaut de ces choix, il existe un risque réel : celui de laisser l’outil prendre le dessus et façonner, par défaut, l’identité même de l’organisation. C’est tout l’enjeu de l’alignement entre les systèmes d’IA et les orientations stratégiques de l’organisation, ou ce qu’on peut appeler l’AI-organization fit.
CONCLUSION
Lorsqu’il s’agit d’intégration des modèles d’IA au sein des organisations, on oublie souvent que ces outils produisent leurs résultats à partir de traces écrites. Or, une organisation ne se résume pas à ses documents. Elle peut être pensée comme un organisme vivant : elle évolue, elle apprend de ses erreurs, s’adapte et ajuste ses trajectoires et stratégies dans un environnement changeant.
L’expérience vécue constitue un élément central de la vie des entreprises. Les différents sous-systèmes de l’organisation (ses équipes, ses processus, ses outils…) sont interdépendants et interconnectés. Ces dynamiques font la spécificité de chaque organisation, sa capacité à construire un équilibre et se maintenir dans la durée.
Or malgré les avancées technologiques, les modèles d’IA peinent à capter cette richesse et ces dynamiques. Ils constituent encore une représentation théorique et abstraite de la réalité des organisations. C’est dans ce contexte que la notion de context engineering peut servir de proxy pour faire le lien avec la réalité de l’organisation dans ce qu’elle a de vécu et de réel.
La difficulté est que cela relève de la spécificité de chaque organisation, ses valeurs, sa stratégie, ou autrement dit sa part d’humain. Peut-on développer une approche d’ingénierie du contexte capable de combler le vide de sens derrière les outils d’IA ? Et comment le faire de manière sécurisée, maîtrisée et itérative ? Ce sont autant de défis qui pourraient aider à façonner l’utilité de ces systèmes au sein des organisations.
RÉFÉRENCES
Altepost, A., Elaroussi, F., Hansen-Ampah, A., Harlacher M., Merx W., (2024), Assessing organizational framework conditions for the successful, human-centered introduction of AI applications. Z. Arb. Wiss. 78, 335–348
Chen Z., Feng Y., He C., Deng Y., Pu H., IPAD: Inverse Prompt for AI Detection – A Robust and Explainable LLM-Generated Text Detector, preprint 2025
Lee J., Lee H., Kim J., Lee K., Kim E, Self-Corrective Task Planning by Inverse Prompting with Large Language Models, preprint 2025
Li H., Klabjan D., Reverse Prompt Engineering, preprint 2025
Shen H., Knearem T., Ghosh R., Yang T., Clark N., Mitra T., ValueCompass: A Framework for Measuring Contextual Value Alignement Between Human and LLMs, preprint 2025
Wixom B., Someh I., Gregory R. (2020), AI alignment: a New Management Paradigm, MIT CIR, XX-11
Pour un exemple pas à pas de l’utilisation du prompting inversé : Le prompting inversé : comment obtenir ce que vous voulez avec Chat GPT ?
Articles similaires

L’IA s’invite au cœur des rédactions historiques : automatisation, hiérarchisation algorithmique, personnalisation… mais à quel prix pour la singularité éditoriale et la confiance du public ?

L'émergence rapide des technologies numériques, de l’IA, et des FinTechs, nourrit une transformation du secteur bancaire traditionnel, redéfinissant à la fois l'offre de services et les modalités d'interaction avec les clients.

La motivation au travail constitue aujourd’hui un enjeu central pour les organisations, tant du point de vue de la performance que de la rétention des talents et de la santé psychologique des collaborateurs.