
L’intelligence artificielle au service de l’administration publique : quelles techniques et quelles spécificités ?

Les budgets importants alloués aux projets d’IA au sein de l’administration publique démontrent la prise de conscience des gouvernements du fort potentiel de l’IA dans ce secteur
Les techniques de data mining et de machine learning (qu’elles reposent sur un apprentissage supervisé ou non) sont très prometteuses pour l’administration publique qui dispose d’un volume important de données
Les cas d'usage montrent le potentiel de l’IA au service des citoyens. Cependant, des problématiques inhérentes à l’administration publique doivent être considérées, comme l’acceptabilité de l’IA ou le risque de lui accorder une trop grande confiance
Début 2019, le gouvernement français a lancé un deuxième appel à candidatures (le premier avait été lancé en 2018) auprès des administrations de l’Etat (ministère, administration centrale, opérateur sous tutelle et service déconcentré) concernant des projets de modernisation intégrant l’Intelligence Artificielle. Il semblerait que le potentiel de l’IA dans l’administration publique soit aujourd’hui pleinement identifié au niveau étatique.
La DINUM – Direction interministérielle du numérique – (ex – DINSIC) et la DITP – Direction Interministérielle de la Transformation Publique – ont intégré comme critères de sélection des projets, les bénéfices potentiels internes et externes pour l’action publique, mais également leur pertinence technique.
Malgré ce contexte d’appel à projets, les administrations sont encore nombreuses à s’interroger sur le potentiel souvent peu exploré de l’intelligence artificielle pour les administrations publiques. Ainsi, nous débuterons cet article par un état des lieux du constat des apports de l’IA aux administrations en France et à l’international. Puis nous nous attacherons à comprendre certaines des techniques utilisées et leur possible application dans différents domaines.
Les deux directions espèrent également que les retours d’expérience issus de ces projets permettront de bénéficier à d’autres acteurs et d’apporter des éclairages sur les bénéfices et enjeux liés à l’intégration de l’IA dans l’administration publique. Nous avons choisi d’exposer quelques cas d’usage que nous jugeons particulièrement pertinents.
Enfin, la DINUM et la DITP accordent également un intérêt à la prise en compte des risques éthiques dans les projets qu’elles étudient. Nous analyserons certaines des problématiques inhérentes à l’utilisation de l’IA et des données dans l’administration publique.
Constat du potentiel de l’IA pour l’administration en France et à l’étranger
Les projets retenus par la DINUM fin 2019 touchaient principalement la gestion de la relation usagers (par exemple, un voice bot pour les utilisateurs du chèque emploi association), le ciblage de contrôles (comme la détection par image des irrégularités d’occupation des sols, des contrôles de restaurants basés sur l’analyse des commentaires des clients ou encore l’identification de zones à risque pour appuyer la priorisation des contrôles de la police de l’environnement) et l’analyse et synthèse d’information (tel que l’extraction de données pour appui des médecins dans la préparation des réunions de concertations pluridisciplinaires, l’exploitation des « lettres de suite » réalisées par les inspecteurs des activités nucléaires pour orienter les contrôles futurs). Parallèlement, une réflexion est menée pour mettre en réseau ces projets et générer de la valeur ajoutée par cette mise en relation.
Le gouvernement français n’est pas le seul à avoir identifié le potentiel de l’intelligence artificielle pour les administrations (accélération du traitement des demandes, pertinence des contrôles, etc.). A l’international, les initiatives se multiplient et permettent d’illustrer la nature du gain espéré. En Chine, de nombreux systèmes de surveillance des citoyens (intégrant notamment la reconnaissance faciale et le croisement de données) sont déjà déployés et le pays compte bien utiliser ces technologies à plus grande échelle et notamment à des fins militaires (conduites de véhicules sous-marins ou encore drones sans pilote).
A l’instar de la Chine et des Etats-Unis, le Québec affiche également de grandes ambitions quant au déploiement de l’IA dans l’administration publique. Mais la province souhaite baliser son usage de manière à y intégrer les enjeux éthiques et s’assurer de retombées positives pour ses citoyens. Ainsi, la volonté politique du Québec de déployer une intelligence artificielle « éthique » est davantage présente que dans les autres pays. Cela s’illustre dans la mise en place par le gouvernement, dès 2017, d’un Comité d’Orientation de la grappe en intelligence artificielle, dont le mandat est d’étudier les impacts de l’IA sur le plan éthique. A titre de comparaison, la Chine, cible des critiques quant aux principes qui guident l’utilisation de l’IA, amorce seulement sa réflexion dans le domaine.
Dans ces différents pays, la prise de conscience du potentiel de l’IA se traduit par des subventions massives accordées par les gouvernements. Le plan budgétaire 2019-2020 du Québec prévoyait d’injecter près de 330 millions de dollars afin de favoriser l’adoption de l’IA entre 2019 et 2024. Pour sa part, la France avait annoncé en 2018, à la suite de la remise du rapport Villani, qu’elle consacrerait 1,5 milliards d’euros d’investissements publics pour le développement et la promotion de l’Intelligence Artificielle d’ici 2022. La Chine, qui ambitionne de devenir leader mondial de l’IA à horizon 2030, aurait déjà investi autour de 70 milliards de dollars dans le domaine et ne compte pas s’arrêter là.
En France, ces investissements ont vocation à se distribuer sur certains secteurs identifiés comme clés (santé, transports, environnement, défense). Mais ils visent également à permettre la réalisation de projets transverses comme le lancement d’un fonds commun de données ou la constitution d’une équipe d’experts en algorithmes pour mener des enquêtes judiciaires. L’administration publique de demain devra en effet se doter des compétences techniques nécessaires à l’implémentation et l’utilisation de l’IA. Les secteurs précités ne pourront tirer plein bénéfice de la technologie qu’en s’assurant la bonne maîtrise de ses techniques.
Des technologies prometteuses pour l’administration publique
La performance d’un grand nombre de techniques d’Intelligence Artificielle bien connues (reconnaissance manuscrite, faciale, croisement de données, agent conversationnel, etc.) se base sur l’utilisation d’algorithmes basés en machine learning, qui peuvent être parfois complexes à appréhender.
Plusieurs techniques reposant sur le data mining et le machine learning sont d’ores et déjà très largement utilisées par les administrations. Le data mining consiste à retraiter des données et à les mettre en relation pour extraire des schémas de données. Cela permet bien souvent de générer de la matière au service du machine learning, c’est-à-dire, la capacité des algorithmes à autonomiser le processus d’apprentissage.
Deux techniques de machine learning peuvent être distinguées : l’apprentissage supervisé et l’apprentissage non-supervisé. Nous proposons de les illustrer ci-après avec un exemple de méthode utilisée associé à une application possible dans l’administration.
Les cartes auto-organisatrices ou auto-adaptatives (ou self-organizing map (SOM) ou cartes de Kohonen (introduites dès 1995 par T. Kohonen)
La technique des cartes auto adaptatives s’appuie sur le principe biologique neuronal (caractéristique des vertébrés) selon lequel chaque neurone est spécialisé dans la réalisation d’une tâche spécifique par l’excitation d’une région particulière du cerveau. De manière analogique, les cartes constituées permettent de représenter un ensemble de données, avec une division par secteur auquel est affecté un point de référence appelé « vecteur référent ».
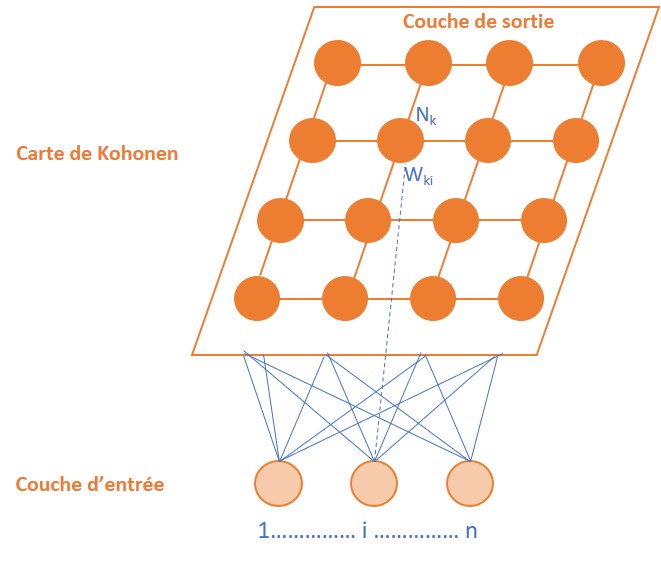
Les cartes auto-organisatrices constituent une des techniques les plus utilisées en machine learning. Elles reposent sur un apprentissage non supervisé dont le principe consiste à introduire un nombre important de données d’entrée sans connaître en amont le résultat obtenu. Le nombre de classes/secteurs en sortie n’est pas prédéterminé ; la machine constitue de manière autonome des groupes homogènes (avec des caractéristiques communes).
Ce principe de regroupement de données par similarités peut être utilisé pour identifier un type de profil particulier comme l’illustre l’exemple ci-dessous :

Réseau de neurones perceptron multicouche
A la différence de la technique des cartes auto organisées, le « perceptron multicouche » est un algorithme d’apprentissage supervisé.
L’architecture de ce réseau se caractérise par la présence de couches successives, comme nous pouvons le visualiser sur le schéma ci-dessous :

Les neurones constitutifs d’une même couche ne présentent pas de connexion entre eux. La couche d’entrée lit les signaux détectés et la couche de sortie est la réponse apportée par le système. Les différentes couches connectent les neurones entre eux avec des poids affectés à chaque connexion. Entre elles, une transformation des variables s’opère par le biais des poids, qui constituent la « programmation » de l’algorithme de l’entrée vers la sortie. Un algorithme de rétropropagation peut être utilisé pour réaliser l’apprentissage le plus fiable possible. Il consiste à mesurer l’écart entre la sortie désirée et la sortie observée et à rétropropager cette erreur à travers les couches dans le sens allant des sorties vers les entrées. Ainsi, le risque d’erreur diminue au fur et à mesure de l’apprentissage.
Le perceptron repose sur un apprentissage supervisé ce qui signifie que l’algorithme s’appuie sur des observations connues préexistantes. Au regard des nombreuses données dont dispose l’administration publique, nous imaginons le potentiel de cette technique de « prédiction ». En s’appuyant sur des éléments connus dans des domaines aussi divers que l’éducation (élèves en échec scolaire), la santé (patients atteints de cancers), l’économie (entreprises présentant des difficultés financières)…, les différentes administrations pourraient, pour chacun d’entre nous, établir une prédiction de nos situations sur toutes les dimensions de notre vie. Si nous écartons les problèmes éthiques que nous discuterions par la suite, les gains potentiels sont immenses. Les apports de ces technologies peuvent être mesurables directement (gains financiers permettant d’anticiper des fraudes ou des faillites d’entreprise) ou plus qualitatifs (répondre au plus près des besoins de chaque citoyen).
Nous décrivons ci-après le déroulement d’un algorithme reposant sur de l’apprentissage supervisé et illustrons son utilisation concrète avec l’identification par la Caisse d’Allocations Familiales de dossiers présentant des indus :

Plus globalement, il est à noter que dans le cadre de la lutte contre la fraude (par exemple dans le cadre de la détection de la fraude à carte bancaire sur Internet), l’utilisation de techniques d’apprentissage supervisé et non supervisé peut être envisagée de manière cumulative. Ces techniques qui permettent les regroupements de données et la prédiction peuvent également être généralisées à de nombreux autres domaines et cas d’usage qui s’avèrent particulièrement pertinents pour appuyer l’administration publique dans l’exercice de ses missions. Nous allons en présenter quelques-uns.
Quelques cas d’usage
Améliorer la gestion de la relation usagers
En 2016, un « Plan d’action interministériel pour des services publics attentionnés » a été élaboré annonçant une nouvelle ère pour l’administration publique, qui se préoccupe désormais très officiellement de la relation avec ses usagers. Parmi les recommandations de ce plan, figuraient notamment « Penser les parcours usagers » ou encore « Continuer à innover et expérimenter dans la Relation de Service ». Le déploiement de l’intelligence artificielle doit s’inscrire dans ces orientations.
Le scope d’intervention de l’administration publique est large, tout comme les potentialités de l’intelligence artificielle pour l’appuyer dans la recherche de l’amélioration de son lien avec les citoyens. Voici quelques missions de l’administration publique dans lesquelles s’inscrit l’IA :

FIG 5. Domaines d’action de l’administration publique sur lesquels l’utilisation de l’IA est particulièrement adaptée[4]
Cibler les interventions de l’administration publique
Parallèlement, l’intelligence artificielle peut appuyer l’administration dans un exercice plus efficient de ses missions. Par exemple, au service d’un meilleur ciblage en amont des contrôles, ou à des fins d’organisation des ressources.
A l’instar de Prévisecours, un projet des pompiers de l’Essonne, basé sur l’exploitation de certaines données, dans l’objectif de prédire les interventions à venir en termes de volume et de géolocalisation. Le modèle utilisé pour « Prévisecours » est basé sur du machine learning, et permet de croiser des données variées comme la salubrité des logements, la météo, la pollution, etc. Il est possible d’imaginer que des initiatives semblables soient mises en œuvre dans d’autres domaines d’intervention.
Extraire et analyser l’information
Dans de nombreux domaines de son exercice, l’administration publique dispose d’un volume important de données archivées au fil des années. Le recours à ces données est parfois nécessaire dans la réalisation de certaines missions et leur processus d’extraction peut se retrouver confronté à une hétérogénéité de supports et/ou formats (manuscrit, numérique, vocal, etc.). L’IA peut s’avérer d’un grand secours dans l’exploitation des données disponibles notamment par le biais de techniques comme le traitement automatique du langage naturel (NLP), la reconnaissance optique de caractères, la reconnaissance des images des visages, etc.
Parmi les secteurs d’application multiples et variés, citons celui de la justice, où les données de jurisprudence peuvent être exploitées afin d’extraire des informations structurées qui appuieront les magistrats dans l’objectivation de leurs décisions. Néanmoins, et nous l’analyserons dans la suite de cet article, pour conserver toute sa pertinence (à savoir une décision cohérente et adaptée à chaque situation), la justice ne pourra s’exonérer d’un regard averti et critique de la part de ceux qui l’exercent.
Evaluer les politiques publiques et aider à la décision
En avril 2018, un robot a brigué la candidature à la mairie de la ville de Tama au Japon. Même si en réalité, un humain en chair et en os se cachait derrière cette candidature, le programme de la campagne promettait une politique « impartiale et objective ».
Si cet exemple reste anecdotique, de nombreux logiciels sont déjà utilisés pour évaluer les politiques publiques. Nous pouvons citer l’exemple de Worksim, un logiciel de simulation basé sur des agents informatiques en interaction qui reproduisent les comportements des acteurs économiques. Il a été utilisé en France en 2016 pour évaluer les conséquences de la loi EL Khomri et son impact sur la politique de l’emploi, sur la base de nombreux critères sociaux. Ces algorithmes ont pour but de simuler les comportements des acteurs économiques, mais en tenant compte du fait que la rationalité est limitée dans un monde complexe. Ils permettent de faire varier certains critères pour analyser les résultats produits et peuvent donc être utilisés en tant qu’outil d’aide à la décision.
Problématiques inhérentes à l’administration publique sensibles aux caractéristiques de l’IA
Si l’administration publique a beaucoup à gagner par la mise en place de certaines techniques d’intelligence artificielle, il n’en reste pas moins qu’elle constitue un champ sensible aux problématiques soulevées par l’IA.
Une révolution de l’administration à engager pour garantir l’acceptabilité de l’IA
L’acceptabilité du déploiement de l’Intelligence Artificielle dans la société, considérant qu’un tel déploiement doit d’abord se faire au service des citoyens, implique avant tout la transparence des algorithmes utilisés et de leur mode de fonctionnement.
Gagner la confiance des administrés passe aussi par prêter attention à leur capacité de compréhension, de pouvoir d’expression voire de décision sur les étapes de mise en œuvre de ces techniques. Cela peut se traduire par une meilleure information mais également la création d’un dialogue avec les entreprises proposant des solutions d’IA, les administrations qui les utilisent et les citoyens. L’administration doit également être garante de l’utilisation de solutions d’IA intégrant les enjeux d’éthique et de transparence auxquels sont sensibles les citoyens. C’est en réalité un changement de paradigme dans la philosophie de l’administration qui doit s’opérer (notamment en France où un trop plein de verticalité et d’opacité est souvent pointé).
Sensible à ces enjeux d’acceptabilité, le gouvernement fédéral du Québec a accordé à un consortium d’entreprises françaises et québécoises opérant dans le secteur de l’aéronautique, une somme de plus de 2,5 millions d’euros afin de financer des travaux sur la compréhension des techniques d’intelligence artificielle considérées comme une « boîte noire ».
L’acceptabilité ne se fera pas sans une certaine transparence à la fois sur les types de modélisations des données mais également sur les données utilisées. Dans ce sens, en France la loi du 7 octobre 2016 pour une république numérique prévoit que les données sources utilisées « lorsqu’une administration fait usage d’un algorithme pour prendre une décision les concernant » doivent faire l’objet d’un droit à l’information des personnes physiques ou morales impliquées (« principe de transparence des algorithmes publics qui servent à fonder les décisions administratives individuelles »).
Une fracture numérique qui peut accentuer les difficultés d’accès au service public
Si garantir l’acceptabilité de l’IA constitue le premier enjeu pour gagner la confiance, assurer son accessibilité n’en reste pas moins crucial. Le déploiement de l’IA ne doit pas se faire au détriment d’une égalité d’accès au service public. La numérisation des démarches administratives et la disparition progressive des guichets physiques fait peser un risque d’isolement vis-à-vis des services publics pour une frange de la population présentant des difficultés de maîtrise des nouvelles technologies ou située en zone blanche.
La pleine acceptabilité de l’IA au sein de la société nécessite d’assurer une certaine transparence sur sa mise en œuvre ainsi qu’un niveau de compréhension et d’accessibilité non discriminatoire. Mais pour l’administration, les enjeux vont au-delà. L’action de cette dernière doit notamment satisfaire à un principe d’équité qui peut être entravé par l’illusion du caractère égalitaire du traitement des données par la machine.
Plusieurs biais à considérer
L’ambiguïté de la « pseudo-objectivité » de l’intelligence artificielle
Il ne faudrait pas oublier que derrière la machine, il y a l’homme qui la « paramètre ». Ainsi, la neutralité de la technologie reste soumise à son entraînement et au but recherché par l’homme. Nous l’avons vu précédemment, dans les techniques de machine learning et particulièrement lorsqu’elles sont supervisées, la phase d’initialisation est cruciale pour la suite de l’apprentissage. Dans le cas de la prise d’une décision administrative, l’homme entraîne la machine selon le but recherché (parfois à des fins politiques dans le cadre de la mise en place de certaines politiques publiques) et le risque est grand qu’il « transmette » certains biais cognitifs humains sur les modèles appliqués.
L’utilisation de l’intelligence artificielle dans le cadre de la mise en œuvre de la législation illustre cette ambiguïté, et comment l’administration doit s’en saisir afin de tirer profit du potentiel de l’IA tout en garantissant la non-reproduction des discriminations et des biais préexistants dans la société. Comme vu précédemment, le droit devient un objet pour l’intelligence artificielle : par ses caractéristiques et potentialités (prédictibilité et objectivité notamment), l’intelligence artificielle peut être un outil permettant de garantir une certaine normativité et équité du droit. L’administration juridique se doit donc de prendre en compte ces changements liés à l’apport des techniques d’IA dans l’exercice de ses missions. Néanmoins, si elle doit en saisir le potentiel, il lui appartient également ne pas sous-estimer ses écueils ni le risque de se voir déposséder de son esprit critique indispensable dans le cadre de l’élaboration des projets de loi.
Boris Barraud, dans son article « Le droit en datas : comment l’intelligence artificielle redessine le monde juridique » oppose ainsi la « normativité étatique » avec la « normativité algorithmique ». Des techniques comme celle des cartes auto-organisatrices ont vocation à classifier automatiquement les données. Le risque est de conduire à une hyper individualisation des situations en permettant de traiter différemment chaque citoyen par le biais de multiples critères (alors que la « normativité étatique » s’attache à dégager des « tendances » générales) conduisant à certaines formes de discrimination.
Il semblerait que la problématique de l’égalité (ou plutôt du risque de non-respect de l’égalité) liée au déploiement de l’IA ait bien été identifiée. En juin 2020, en France, le Laboratoire de l’Egalité a publié un « Pacte pour une intelligence artificielle égalitaire ». Les recommandations, saluées par certains membres du gouvernement, sont orientées sur les discriminations de genre mais peuvent être extrapolées à d’autres types de discrimination. Elles portent entre autres sur un nettoyage des bases de données (suppression de certains critères pouvant orienter la décision, garantir la neutralité des assistants virtuels…). Le potentiel de l’intelligence artificielle dans la garantie de l’égalité de traitement réside dans la possibilité de corriger cette subjectivité (ce qui est impossible de faire chez l’humain).
Le défi réside dans le délicat équilibre à trouver entre l’exploitation de l’immense potentiel de l’IA, et la garantie de performance et d’objectivité, tout en préservant certaines valeurs inhérentes à l’administration publique. Cette dernière se doit de continuer à œuvrer, avec toujours comme mission première d’être au service de l’intérêt général et du citoyen.
Les prophéties autoréalisatrices
L’autre biais identifié dans le domaine de la justice et qui cette fois se situe au niveau de la relation entre la technique et le citoyen est celui des prophéties autoréalisatrices. Comme l’explique Boris Barraud, des juges pourraient orienter leurs décisions afin qu’elles soient conformes à la machine (qui ne peut s’appuyer que sur la jurisprudence en tant que critère). De la même manière, des citoyens confrontés à des guichets numériques (et non plus physiques) et freinés par une aisance limitée avec les technologies, pourraient ne plus recourir à certaines demandes (en estimant que les critères « objectifs » ne sont pas remplis ou que la machine ne saisira pas l’entièreté et la variabilité de leur situation). Rien n’est moins sûr que le robot candidat de la ville de Tama ait été le meilleur maire de la ville malgré sa garantie de neutralité…
Il faudra ainsi veiller à ce que ces algorithmes au pouvoir prédictif ne deviennent pas prescriptifs, que ce soit pour la prise de décision (en contraignant d’une certaine manière le libre-arbitre) ou dans l’imaginaire des citoyens qui les utilisent.
——–
Le 23 décembre 2020, le député des Côtes d’Armor, Eric Bothorel, a remis au Premier ministre, Jean Castex, le « Rapport sur la politique publique de la donnée, des algorithmes et des codes sources ». Ce rapport met à la fois en avant la « puissance de la donnée » et son potentiel notamment dans l’administration publique (amélioration du service publique, restauration de la confiance, évaluation des politiques publiques) tout en avançant un certain nombre de recommandations. Selon le rapport, il est nécessaire de faire de la donnée une priorité gouvernementale afin que les services publics se saisissent de toute leur responsabilité dans son exploitation.
La culture de la fonction publique doit également se réinventer et cela passera notamment par le recrutement de personnes compétentes dans le domaine. Les citoyens devront être associés à l’ensemble des travaux menés afin d’encourager la confiance dans les innovations proposées.
A la lecture de ce rapport, nous pouvons conclure par cette interrogation : La « libération » de la donnée, indispensable au déploiement de l’IA, n’est-elle pas un enjeu crucial pour l’administration publique de demain ? Nous pouvons d’ores et déjà répondre que cela ne se fera pas sans le respect d’un cadre strict tant au niveau législatif (exigences du RGPD, etc.) qu’éthique.
Sources :
- Joëlle Gélinas J., Lavoie-Moore M., Lomazzi L., Qui profite des investissements publics en intelligence artificielle ?, Institut de recherche et d’informations socioéconomiques, mars 2019
- Ministère de l’Economie et de l’Innovation, Programme Innovation Soutien aux projets d’innovation en intelligence artificielle, Gouvernement du Québec, janvier 2020
- France Terre d’Intelligence Artificielle, Entreprises.gouv.fr, consulté en février 2021
- Algorithmes publics : Accompagner les administrations dans l’usage responsable des algorithmes publics, le blog d’Etalab, consulté en février 2021
- Barraud B, Le droit en datas : comment l’intelligence artificielle redessine le monde juridique, Revue Lamy droit de l’immatériel, 2019
- Barraud B., L’algorithmisation de l’administration, Revue Lamy droit de l’immatériel, 2018
Machine learning :
- WikiStat, Réseaux de neurones, Université de Toulouse, consulté en janvier 2021
- Parizeau M., Le perceptron multicouche et son algorithme de rétropropagation des erreurs, Université de Laval, septembre 2004
[1] Schéma inspiré de Ramzi DZIRI et Nadine LEVRATTO, Diversité des mondes de production et des voies d'accession à la rentabilité des petites entreprises : une analyse par les cartes auto-organisatrices [2] https://www.becoz.org/these/memoirehtml/ch06s04.html [3] Ce schéma s’appuie sur les sources suivantes : Bilan 2018 des actions de lutte contre la fraude et actions de contrôles, Assurance Maladie 2019 e-Fraud Box : Détection et Investigation de la fraude à la carte bancaire sur Internet Le data mining aiguillonne la detection des cas de fraudes à la CAF [4] Agents conversationnels et assistants virtuels en capacité de traiter des questions récurrentes de manière automatique et de rechercher des informations pertinentes sur un thème donné
Articles similaires

234 agents de la DINUM quittent Windows : avant d’être une migration générale, il s’agit d’un test de souveraineté numérique. Peut-on le lire comme une stratégie de réduction progressive de dépendances ?
Nous avons analysé en détail le cadre français et européen de la réforme de la facturation électronique, ainsi que ses impacts concrets pour les organisations.

Dans un article intitulé “Street-level bureaucracy in weak state institutions: a systematic review of the literature”, Rik Peeters et Sergio A. Campos se concentrent sur les bureaucrates de proximité dans les démocraties fragiles, où les ressources, la supervision et la confiance publique font défaut.